Introduction
The objective of our ML system is to be able to extract the image type and color from the images of the advertisers' inventories.
Currently supported values:
Image type:
Dealer, Stock, Placeholder
Color:
Black, Blue, Brown, Burgundy, Green, Grey, Orange, Pink, Purple, Red, White, Yellow
The classification of the images is triggered after an SRPScrape process finished collecting the inventory data of an advertiser. The ML server responds with the type and color of each image, using the cached values if the image was previously tagged. If any of the images cannot be downloaded to be tagged they are skipped.
So far we've worked with two different approaches for image tagging.
It's important to note that only the Image Type model is managed by us. The color model was created by another company and it's not under our control.
ML Results caching
Most of the advertisers' inventories don't change too much from day to day, in order to avoid classifying the same images multiple times we use a cache system in the ML servers.
The first time an image arrives at the ML System we calculate an image key based on different data from the request, such as the HTTP headers. After the image is classified we store an entry for that image key with the image type and color.
This process improves the ML performance by a lot because it avoids downloading and classifying all the images from the advertisers every day. It also allows the existence of manual fixes of the image classifications done by our staff or the client.
There is an important caveat, however. In order for the cache system to work optimally, the CDNs used by advertisers have to provide these HTTP headers with the image metadata for us to be able to create a correct image_key.
Some advertisers work with CDNs that don't use the aforementioned information correctly or it is unexistent, in these cases we have to download and use the raw data of the image to create the key.
Known weaknesses and issues
Edit
Weakness: Model Accuracy decays over time
Our datasets are created from images that are currently within our systems.
This causes the accuracy of classifications to decay over time due to new advertisers coming to the system with different types of images.
The periodical retrains of the model are done to mitigate this decay.
The decay in the accuracy for non-car vehicles is even worse because most of the new advertisers are only car dealers. This makes that over time, the % of non-car vehicles in the training data set is lower and lower, making the retrains not so effective in mitigating the decay of accuracy for other vehicle types
Weakness: High overall accuracy and extreme local accuracy values
After a new iteration of models is trained, we test them against the test data set to extract metrics as accuracy or recall. The accuracy of the models against the test set is usually around 90-94%.
Images of the same advertiser tend to be similar to each other. This causes the local accuracy (accuracy within the advertiser) to usually present more extreme values.
Advertisers with easy to classify images will have accuracies of around 100%
Advertisers with conflicting images will have lower accuracies
Issue: Crop of Images with multiple vehicles
When the crop of an image is extracted, the model identifies all the vehicles of the image and extracts the biggest of all. This usually doesn't cause issues because normally the vehicle that we want the advertiser wants to highlight is the biggest but some problematic Placeholder images were found where the crop made it very difficult to identify it as a placeholder image.
Criteria for Image tagging
We use the following criteria to tag the images that are going into the training dataset
Dealer Images: Images of real vehicles
Stock Images: Computer generated images with white background
In previous models, we also included all types of CGIs but it lowered the overall accuracy of the model and caused other issues.
Here you can find a list with all the datasets that were used to train the current and past ml models
Understanding the results from ML
The data returned from the ML server is appended to the scrapped vehicles and stored in the advertiser's Sitemap.
When you take a look at the sitemap image and color classification you will see something like this:
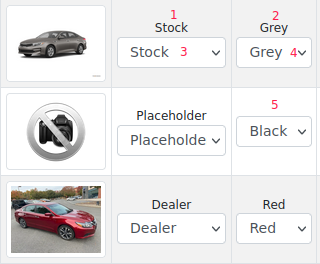
Image Type received from ML system
This value defaults to “Placeholder” if the ML system could not return a value
Color received from ML System
This value defaults to null if the ML system could not return a value
If the color value is configured in the scrape the ML classification for the model is not applied
Image Type Manual fix
Image Type manual fix list selects the value returned from the ML system or defaults to Placeholder if None is received.
Color Manual fix
Color manual fix list selects the value returned from the ML system or defaults to “Black” if None is received
Example of Placeholder tagged from ML system: {Image Type = Placeholder, Color = None}
As you see, as color is not tagged, 5 is not showing anything
Previously tagged Placeholders were {Image Type = Placeholder, Color = 'N/A'}. If you find some of these they are cached values.
Edit
{kind=link}
When you change any value from the Manual fixes list and press the “update” button at the bottom of the list the following happens:
A historical entry of manual fix is stored in the DB with information of what/who/when the change was made
The change is pushed to the ML server to modify the cached values for the image type/color of that image
Edit
Understanding "Weird" results
There are some cases when by just taking a look at the advertiser sitemap you know that something went wrong with the classification. Here is a list of known cases that can happen:
ML System failed to respond to the request
How to identify:
Lot of images classified as {Image Type = 'Placeholder', Color = 'None'} when they are not obvious placeholder
Example:
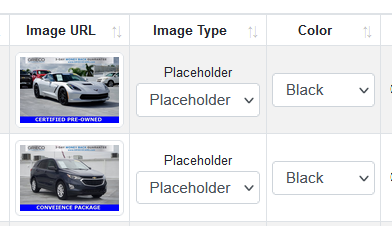
Solution:
Relaunch the scrape and if the problem persists contact the dev team.
Placeholder manual fix made by advertisers
How to identify:
The image is classified as {Image Type = 'Placeholder', Color != 'None'}
Example:

Solution:
Manually retag it back or just ignore it. After all the last word on the classification comes from the advertisers.
Different criteria for image types between the advertisers and us
This case documented on 2021-11 is a good example of discrepancies in classifications.
There were two problematic situations happening simultaneously:
They used digitally created/enhanced images that under our criteria were “Stock” Images so we manually retagged but the advertiser considered them Dealer images
We concluded that we would only manually retag OBVIOUS misclassifications
We concluded that we would only add to the ML training sets significative examples of each class leaving out conflicting images.
The CDN that distributed the images changes the URL and image headers after a few days
This makes the manual retag to not “stay” because for us the image coming after a few days is different due to the image_key calculation
This is a hard case to identify and solve so it probably has to be addressed on an advertiser to advertiser way when it happens.
Examples of conflicting images:




Vehicles 1 & 2 are real cars or very realistic CGI (image 1?) over a static background.
Vehicles 3 & 4 are very similar images from two different dealers.
Image | ML Classification | Client classification | Issues |
|---|---|---|---|
1 | Dealer | Stock | Incorrect classification by the ML System “Not in Stock … on Order”. Cannot add this type of image to the dataset as a Stock image because it will damage the accuracy of dealer images. |
2 | Dealer | Dealer | Correct classification. These type of correct classifications would be damage by adding examples as Image 1 to the Stock training set. |
3 | Dealer | Stock | Very similar to Image 4. Clients differ on which type it is. |
4 | Dealer | Dealer | Very similar to Image 3. Clients differ on which type it is. |